|
Jun is a Senior Machine Learning Engineer at Salesforce Research, working on multimodal LLM. He earned his Ph.D. degree from University of Maryland, College Park, where he was honored to be co-advised by Prof. Larry S. Davis and Prof. Joseph F. JaJa. His research primarily focuses on multi-modal learning, object detection, and 3D scene understanding. Currently, he is on the job market. Recently, Jun has been fortunate to work with Dr. Kishore Prahallad (Apple), Dr. Mingfei Gao and Dr. Ran Xu (Salesforce Research), and Dr. Siheng Chen (Mitsubishi Electric Research Labs). Prior to that, he obtained his M.S. degree in Electrical and Computer Engineering from University of Michigan, Ann Arbor in 2017 and B.S. degree from Beijing Institute of Technology, China in 2015. Email: junwong [AT] terpmail [DOT] umd [DOT] edu Google Scholar / Semantic Scholar / DBLP / LinkedIn / GitHub |

|
|
|
|
|
|
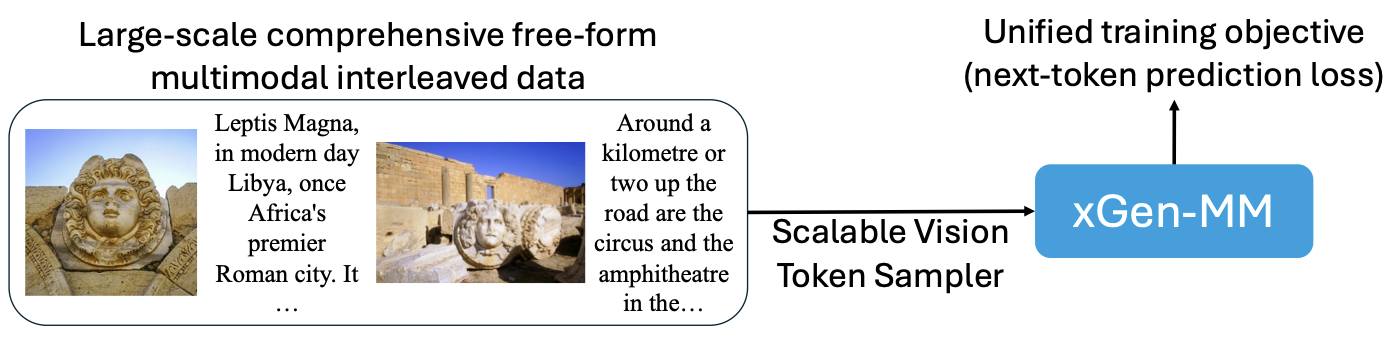
Le Xue*, Manli Shu*, Anas Awadalla, Jun Wang, An Yan, Senthil Purushwalkam, Honglu Zhou, Viraj Prabhu, Yutong Dai, Michael S Ryoo, Shrikant Kendre, Jieyu Zhang, Can Qin, Shu Zhang, Chia-Chih Chen, Ning Yu, Juntao Tan, Tulika Manoj Awalgaonkar, Shelby Heinecke, Huan Wang, Yejin Choi, Ludwig Schmidt, Zeyuan Chen, Silvio Savarese, Juan Carlos Niebles, Caiming Xiong, Ran Xu arXiv, 2024 arXiv / code / dataset / VentureBeat coverage Open-sourced multimodal Large Language Models (MLLM). |

|
Jieyu Zhang, Le Xue, Linxin Song, Jun Wang, Weikai Huang, Manli Shu, An Yan, Zixian Ma, Juan Carlos Niebles, Silvio Savarese, Caiming Xiong, Zeyuan Chen, Ranjay Krishna, Ran Xu arXiv, 2024 arXiv / code / dataset / VentureBeat coverage A scalable system generating 10M+ vision-centric instructions, improving multimodal benchmark by 8%. |
|
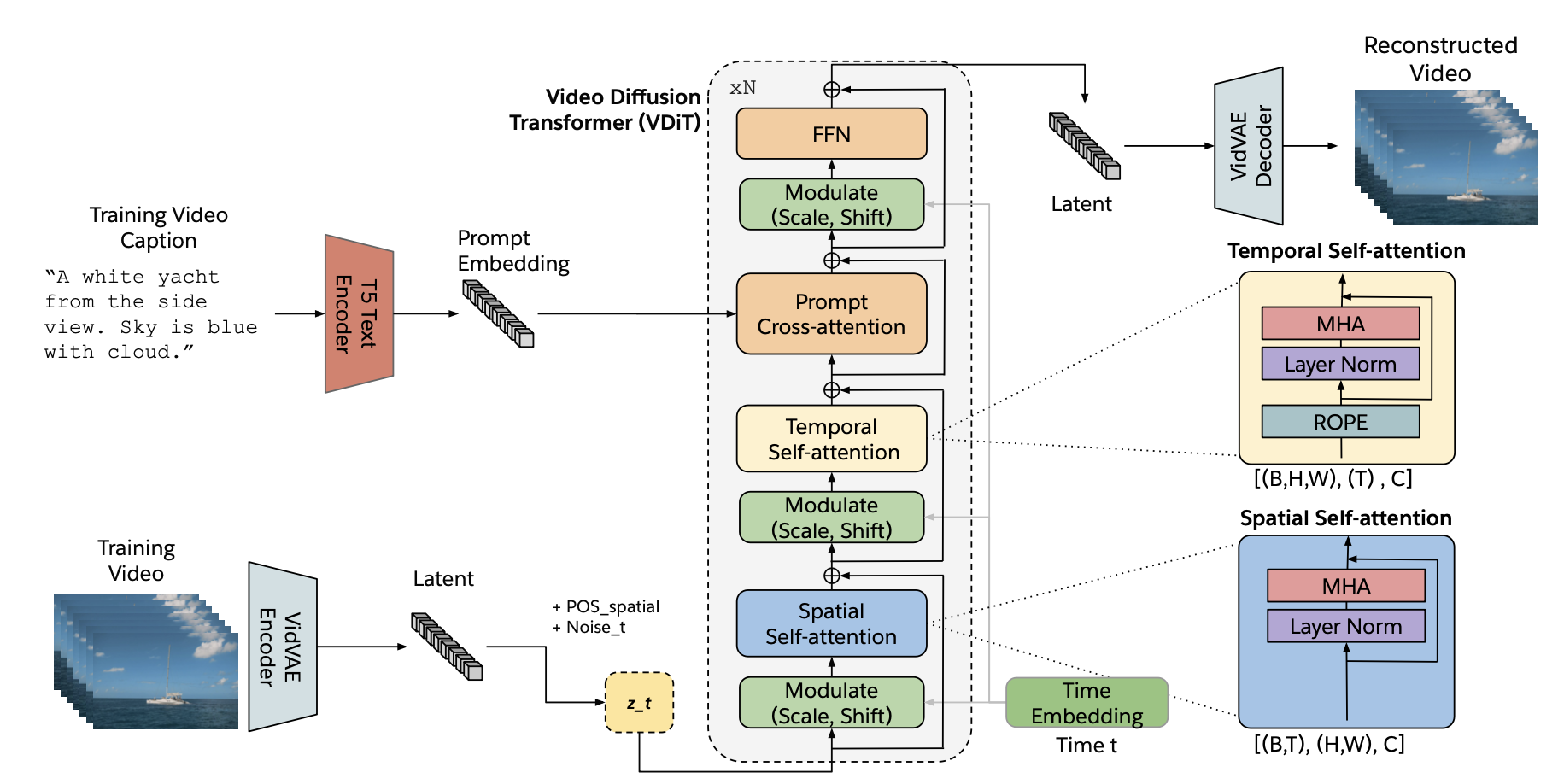
Can Qin, Congying Xia, Krithika Ramakrishnan, Michael Ryoo, Lifu Tu, Yihao Feng, Manli Shu, Honglu Zhou, Anas Awadalla, Jun Wang, Senthil Purushwalkam, Le Xue, Yingbo Zhou, Huan Wang, Silvio Savarese, Juan Carlos Niebles, Zeyuan Chen, Ran Xu, Caiming Xiong arXiv, 2024 arXiv / code A T2V model leveraging VideoVAE compression and Diffusion Transformer. |
|
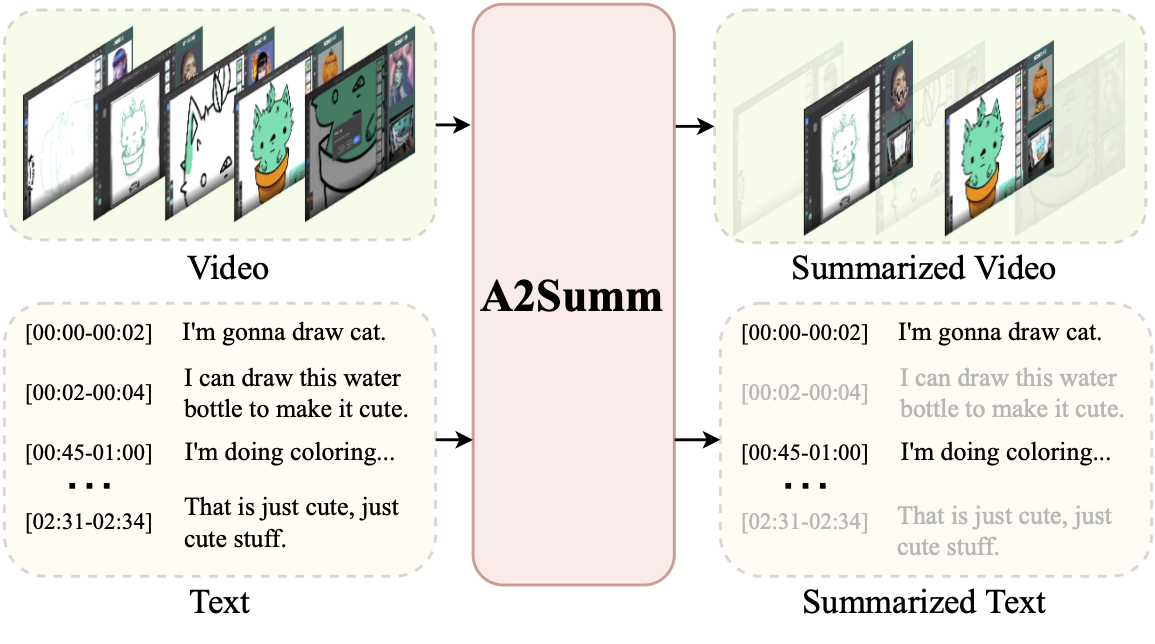
Bo He, Jun Wang, Jielin Qiu, Trung Bui, Abhinav Shrivastava, Zhaowen Wang CVPR, 2023 arXiv / code / project / bibtex Multimodal summarization that summarizes video frames and text sentences with time correspondence. |

|
Jun Wang, Mingfei Gao, Yuqian Hu, Ramprasaath R. Selvaraju, Chetan Ramaiah, Ran Xu, Joseph F. JaJa, Larry S. Davis BMVC, 2022 arXiv / code / poster / bibtex The first generic text-aware question-answer generation approach for Text-related VQA. |
|
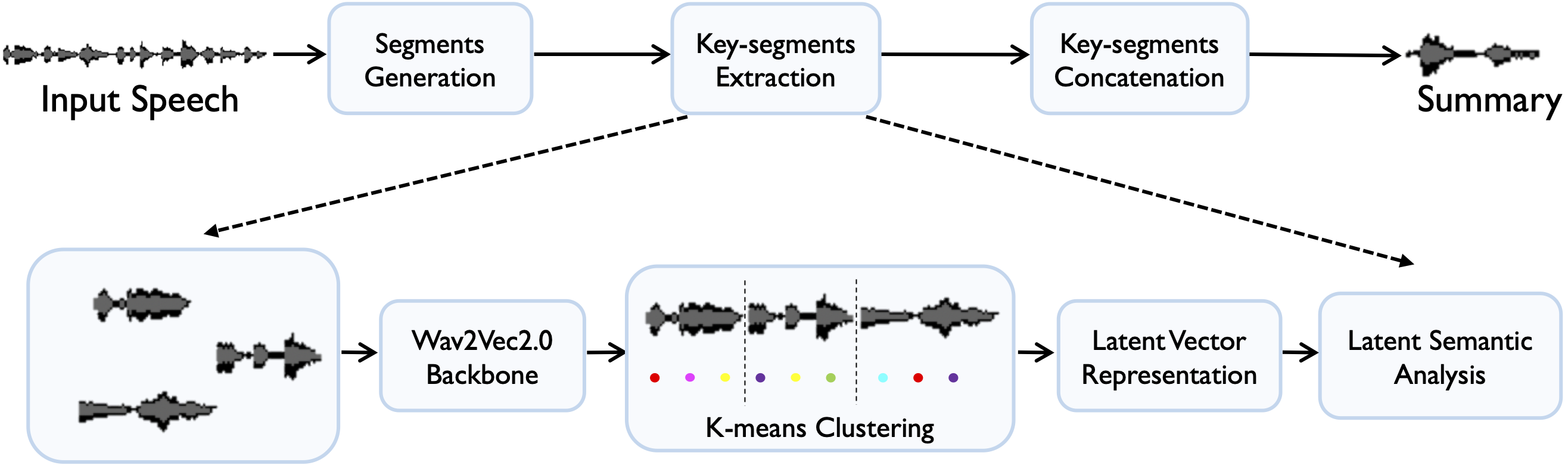
Jun Wang INTERSPEECH, 2022 arXiv / code / slides / bibtex The first automatic speech summarization system with Wav2vec 2.0. |
|
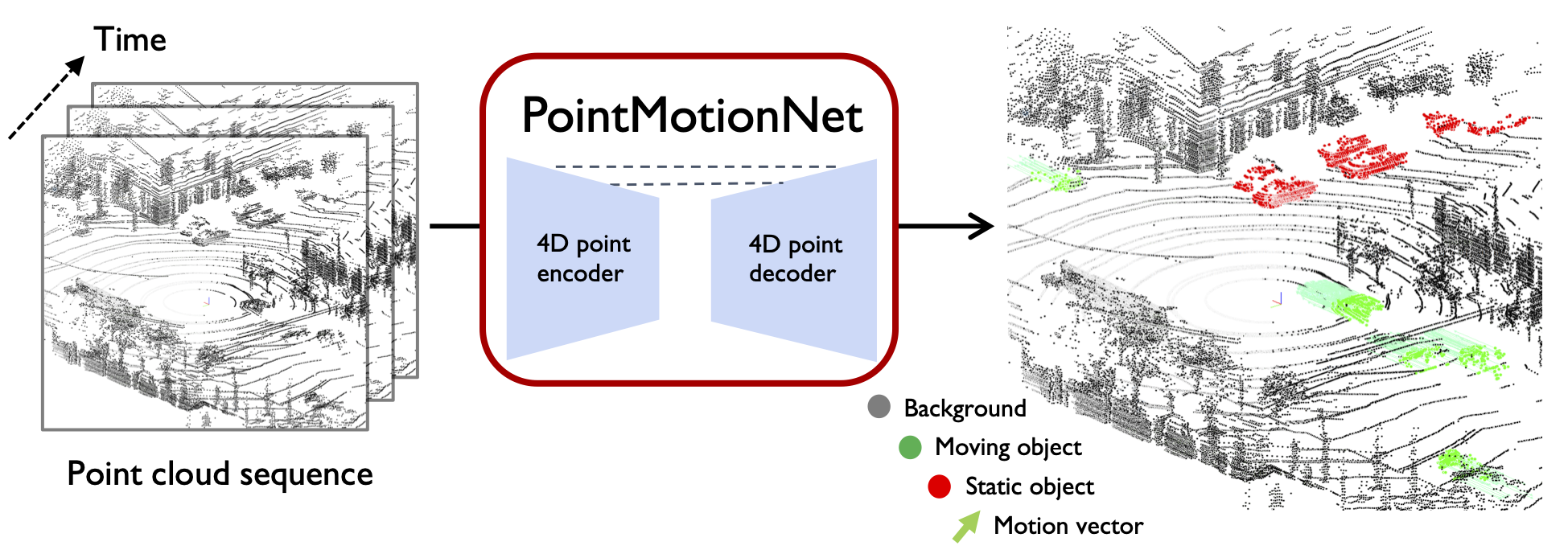
Jun Wang*, Xiaolong Li*, Alan Sullivan, Lynn Abbott, Siheng Chen * denotes equal contribution. WAD, CVPR, 2022 arXiv / bibtex 3D motion learning with a novel point-based spatiotemporal convolution operation module. |
|
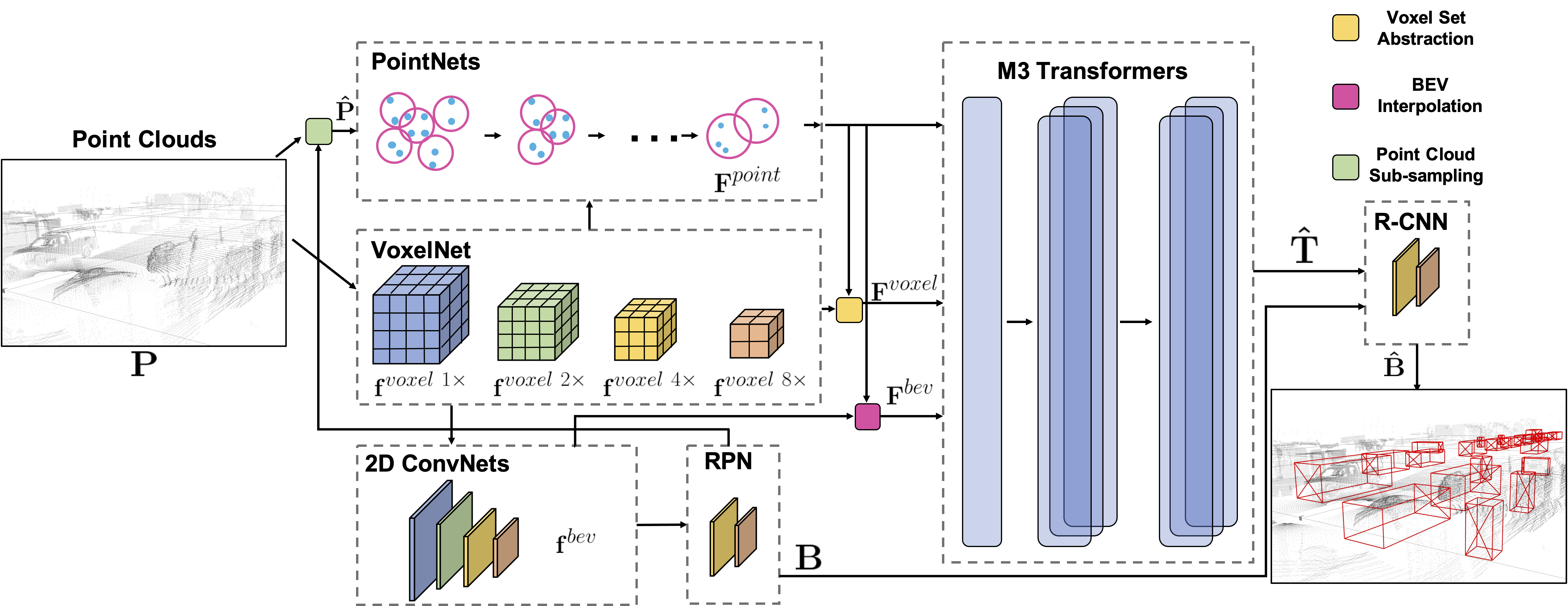
Jun Wang*, Tianrui Guan*, Shiyi Lan, Rohan Chandra, Zuxuan Wu, Larry S. Davis, Dinesh Manocha * denotes equal contribution. WACV, 2022 arXiv / code / slides / bibtex The multi-representation, multi-scale, mutual-relation 3D object detector with transformers. |
|
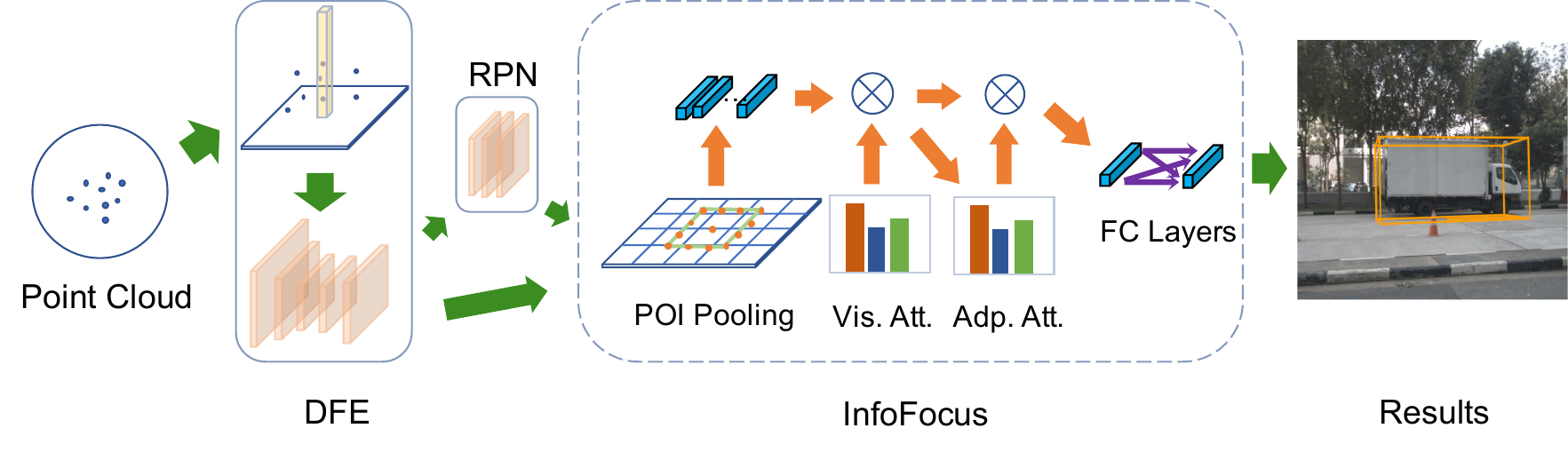
Jun Wang*, Shiyi Lan*, Mingfei Gao, Larry S. Davis * denotes equal contribution. ECCV, 2020 arXiv / slides / bibtex 3D Object Detection with the effective dynamic attention module. |
|
|
|
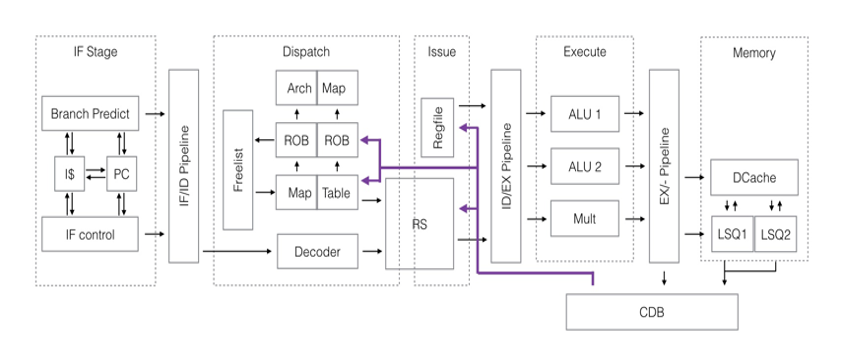
Ruobai Feng, Wang Cao, Jun Wang, Yujun Yan, Jiapeng Zhao EECS 470 Computer Architecture, 2016 The two-way superscalar SMT processor design based on MIPS R10K out- of-order execution architecture. |
|
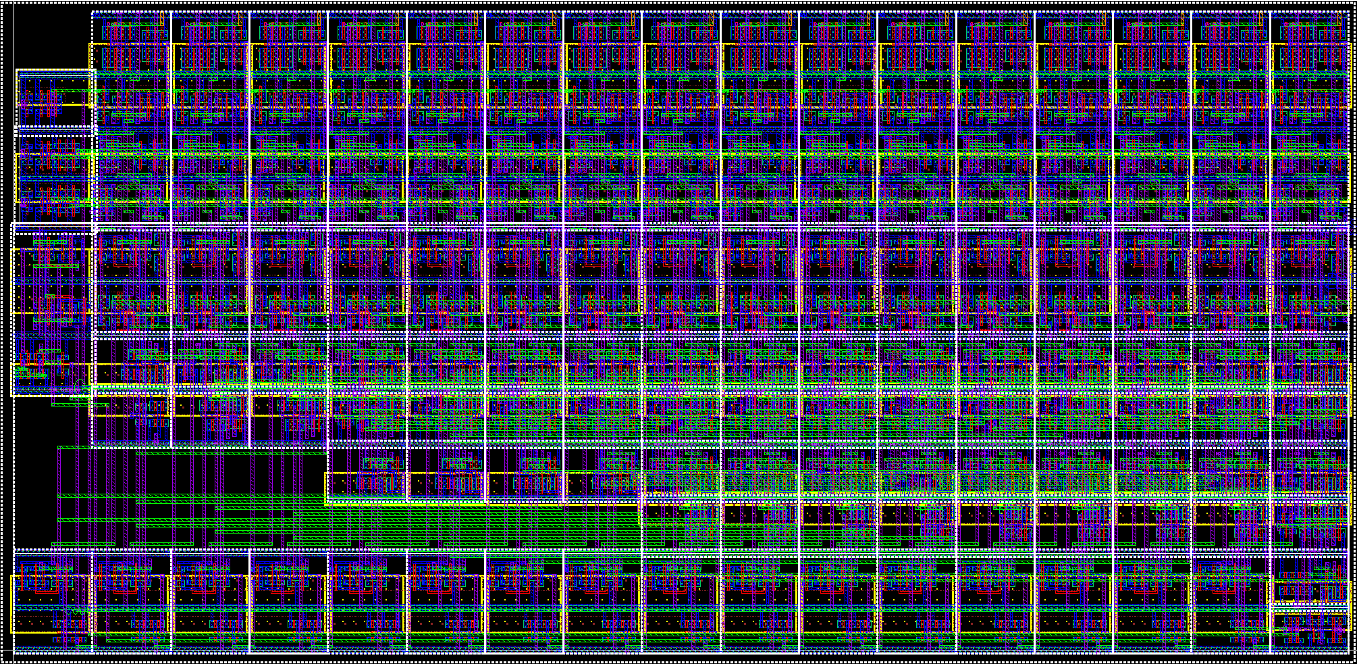
Farzad Asgarian, Harsha Chawla, Isaac Jarman, Cody Piekarz, Jun Wang EECS 427 VLSI Design I, 2015 The baseline processor design with a customized kogge-stone adder based on a 16-bit RISC architecture using IBM’s 130nm CMOS process. |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|